Ausgangslage des Falls
Nach den vorliegenden Informationen waren zunächst mehrere Festplatten ausgefallen. Nach einem anschließenden Stromproblem wurde der RAID-Verbund vom MegaRAID-Controller nur noch als „Foreign Configuration“ erkannt. Der Import der vorhandenen Konfiguration schlug mit dem Hinweis auf eine unvollständige Foreign-Konfiguration fehl. Nach Angaben des Kunden wurden weder eine Initialisierung noch ein Rebuild durchgeführt.
Bei der ersten technischen Bestandsaufnahme am Server wurden der Controllerstatus, die vorhandene RAID-Topologie und die Zuordnung der 96 Festplatten erfasst. Dabei zeigte sich ein RAID 60 mit einer Gesamtkapazität von rund 1,279 PB, aufgebaut aus drei RAID-6-Gruppen mit jeweils 32 Festplatten.
Die zentrale Herausforderung bestand damit nicht nur in den ausgefallenen Laufwerken, sondern in der exakten Rekonstruktion der gesamten RAID-Geometrie. Bereits eine falsch zugeordnete Festplatte, ein abweichender Offset oder eine fehlerhafte Gruppierung kann dazu führen, dass das Dateisystem nur teilweise oder inkonsistent lesbar ist. Deshalb mussten Reihenfolge, Gruppenstruktur, Stripe-Größe, Offsets und Paritätslogik vollständig nachvollzogen und korrekt abgebildet werden.
Ubuntu Linux für die Datenrettung vorbereiten
Im ersten Schritt wurde ein separates Ubuntu-Rettungssystem auf unabhängiger Hardware installiert und nur für den Datenrettungsprozess eingerichtet. Für solche Arbeiten ist Linux in der Praxis besonders geeignet, weil sich Blockgeräte streng kontrollieren lassen und das Kernel-Target-Subsystem LIO über targetcli lokale Storage-Ressourcen als Block-Storage exportieren kann, etwa über iSCSI. Die targetcli-Manpage beschreibt ausdrücklich, dass sich lokale Dateien, Volumes und Blockgeräte als Storage Objects anlegen und über Netzwerk-Fabrics bereitstellen lassen.
Wichtig war dabei nicht die bloße Installation des Betriebssystems, sondern die konsequente Reduktion aller Automatismen. Kein automatisches Mounten, kein versehentliches Initialisieren von Datenträgern, kein unkontrolliertes RAID-Assembly. Bei einer MegaRAID Datenrettung mit dieser Größenordnung ist das Rettungssystem nicht einfach ein Arbeitsplatzrechner, sondern die kontrollierte Quellplattform für alle weiteren Analysen.
Alle Festplatten kernelseitig schreibgeschützt einbinden
Im zweiten Schritt wurden die 96 HDDs über SAS-HBA-Controller einzeln an das Rettungssystem angebunden, bewusst nicht als produktiv importierter RAID-Verbund. Ziel war, jedes Medium als eigenes Blockgerät sichtbar zu machen und sofort auf Kernel-Ebene schreibgeschützt zu markieren. Linux stellt dafür mit blockdev genau die passenden Mechanismen bereit: --setro setzt ein Blockgerät auf read-only, --getro prüft den Status. Das Handbuch weist zugleich darauf hin, dass bereits aktiv read-write genutzte Zugriffe dadurch nicht rückwirkend neutralisiert werden; die Schreibsperre muss also vor jeder weiteren Interaktion gesetzt und verifiziert werden.
Genau dieser Punkt ist für professionelle Server Datenrettung entscheidend. Wer Quellmedien zuerst sichtbar macht und erst danach über Schutzmechanismen nachdenkt, riskiert unnötige Metadatenänderungen durch Betriebssystem, RAID-Tools oder Dateisystem-Scanner. In einem großen RAID-60-Fall mit XFS ist das besonders kritisch, weil schon kleinste unbeabsichtigte Schreibzugriffe die spätere Beweis- und Konsistenzlage verschlechtern können. Deshalb galt hier eine klare Reihenfolge: zuerst HBA-Passthrough, dann Kernel-Read-only, erst danach Analyse.
Laufwerke über einen schreibgeschützten iSCSI-LUN bereitstellen
Im dritten Schritt wurden die 96 schreibgeschützten Quellmedien über Ubuntu als ein readonly iSCSI-LUN am Analyse-PC bereitgestellt. Die Festplatten blieben dabei am Ubuntu-System angeschlossen, während die Rekonstruktion in der PC-3000 Data Extractor RAID Edition durchgeführt wurde.
Der iSCSI-LUN wurde zusätzlich mit Write-Protection konfiguriert. Dadurch standen alle 96 HDDs der RAID-Analyse zur Verfügung, ohne dass von der Analyseseite Schreibzugriffe auf die Originalmedien möglich waren.
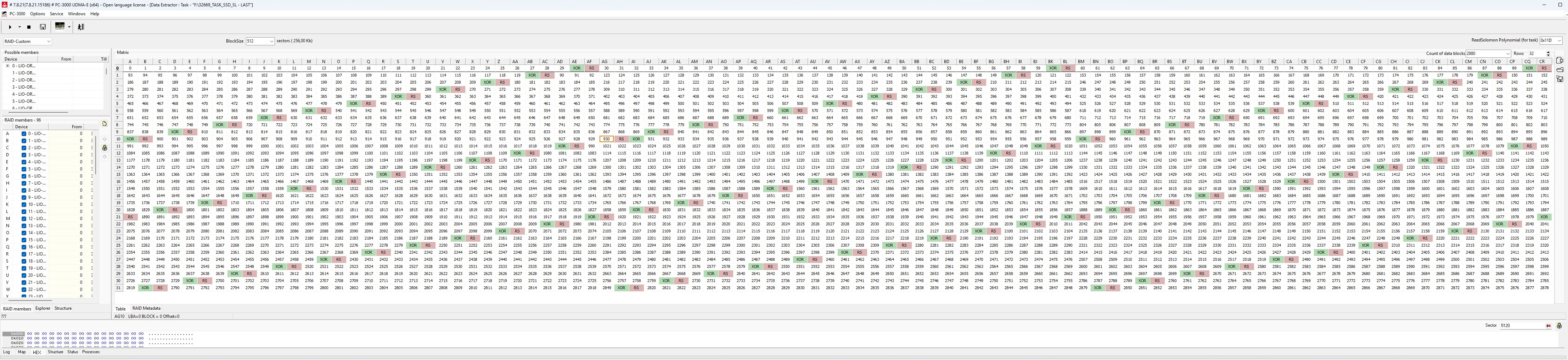
Die Matrix im PC-3000 rekonstruieren
Im vierten Schritt wurde in PC-3000 Data Extractor die RAID-Matrix manuell nachgebildet. Basis dafür war die zuvor gesicherte Controller-Topologie: drei untergeordnete RAID-6-Gruppen, darüber ein RAID-60-Gesamtverbund mit 96 Mitgliedern. Für die Rekonstruktion reichte es deshalb nicht aus, nur eine lineare Disk-Reihenfolge zu setzen. Entscheidend waren die korrekte Zuordnung jedes Members zu seinem RAID-6-Span, die richtige Reihenfolge innerhalb der Gruppen sowie die Abstimmung von Blockgröße, Offsets und Paritätslogik.
Matrix-Ansicht der rekonstruierten RAID-Konfiguration in PC-3000 Data Extractor
Gerade hier trennt sich Standarddiagnose von echter MegaRAID Datenrettung. Ein RAID 60 verhält sich eben nicht wie ein einzelnes breites RAID 6, sondern wie ein Stripe über mehrere eigenständige RAID-6-Sets. Entsprechend muss die Matrixrekonstruktion auch auf dieser Logik aufsetzen. Die visuelle Kontrolle in PC-3000 war deshalb ein zentraler Arbeitsschritt: Erst wenn Member-Reihenfolge, Gruppierung und Paritätsverhalten konsistent sind, lohnt überhaupt der Übergang zur Dateisystemebene.
Das XFS-Dateisystem prüfen
Im fünften Schritt wurde das rekonstruierte Volume in PC-3000 Data Extractor vollständig geprüft. Dabei wurden die XFS-Strukturen sowie die Verzeichnis- und Dateisystemkonsistenz innerhalb der rekonstruierten RAID-Matrix analysiert.
Erst nach erfolgreicher Validierung der RAID-Geometrie und des XFS-Dateisystems wurde mit der kontrollierten Sicherung der wiederhergestellten Daten begonnen. Schreibende Reparaturen am Originalverbund wurden konsequent vermieden.
Die Daten auf externe JBODs sichern
Im letzten Schritt wurden die rekonstruierten Daten auf eine externe JBOD-Zielplattform gesichert. Bei einem vom Controller gemeldeten Volumen von 1,279 PB bedeutet das praktisch ein Sicherungsziel im Bereich von rund 1,3 Petabyte, inklusive sauber geplanter Reserve für Dateisystem-Overhead, Verifikation und eventuelle Wiederholungen einzelner Kopierläufe.
Die Sicherung der RAID-Daten erfolgte erst nach umfangreichen Prüfungen. Sowohl die mathematische Konsistenz der rekonstruierten RAID-Matrix als auch der XFS-Scan mussten übereinstimmende und plausible Ergebnisse liefern. Erst danach wurden die wiederhergestellten Daten auf externe JBOD-Systeme übertragen. Damit konnte der MegaRAID-Server mit RAID 60, 96 HDDs und rund 1,3 Petabyte Datenbestand erfolgreich rekonstruiert und ausgelesen werden.
Was war bei der RAID-Datenrettung ausschlaggebend?
- Die Einrichtung eines separaten Ubuntu-Systems für den Rettungsprozess
- Die schreibgeschützte Anbindung der 96 Festplatten über einen iSCSI-LUN an den Analyse-PC
- Die technischen Möglichkeiten der PC-3000 Data Extractor RAID Edition, mit denen sich die komplexe RAID-60-Matrix analysieren und korrekt nachbilden ließ